


G検定
スキルチェックテストとは
このテストは、G検定*に合格するために抑えておくべきAI・機械学習・ディープラーニングの
知識が、どの程度身についているかチェックするための簡易試験です。
問題を解いたら自分の答えをメモしていただき、解答を見て自己採点を行ってください。
合計点数からあなたの現在の知識レベルを判定し、おすすめの試験対策方法が分かります。
*G検定(AIジェネラリスト検定)とは、日本ディープラーニング協会が主催する、
AIや機械学習・深層学習の網羅的な知識を検定する試験です。
問題(全20問)
AI・パーセプトロン
問1. AI(人工知能)とは
次の文章を読み、空欄に最もよく当てはまる選択肢を選べ。
「AI」や「人工知能」と聞いてイメージするものは人によって異なる。 (ア)型人工知能は「(イ)AI」とも呼ばれ、特定のタスクに限定せず、人間と同様、もしくはそれ以上の汎化能力を持ち合わせたAIと定義されている。多くのSF作品に登場する人型ロボットは、プログラムされた知的作業以上に柔軟に対応する。 一方で、(ウ)型人工知能は「(エ)AI」とも呼ばれ、ある特定のタスクを、人間と同等、もしくはそれ以上の精度で遂行するAIと定義される。たとえば、囲碁の戦術を学習したAIである(オ)は、韓国のプロ棋士イ・セドル氏に勝利を収めた(2016年)。しかし囲碁の能力を将棋に応用することは難しい。そのため、汎化能力の高い(ア)型人工知能とは区別され、「(ウ)型人工知能」と呼ばれる。
(ア) (イ)に該当する選択肢
- (ア)汎化(イ)弱い
- (ア)汎化(イ)強い
- (ア)特化(イ)弱い
- (ア)特化(イ)強い
(ウ) (エ)に該当する選択肢
- (ウ)汎化(エ)弱い
- (ウ)汎化(エ)強い
- (ウ)特化(エ)弱い
- (ウ)特化(エ)強い
(オ)に該当する選択肢
- elmo
- Stockfish
- Watson
- AlphaGo
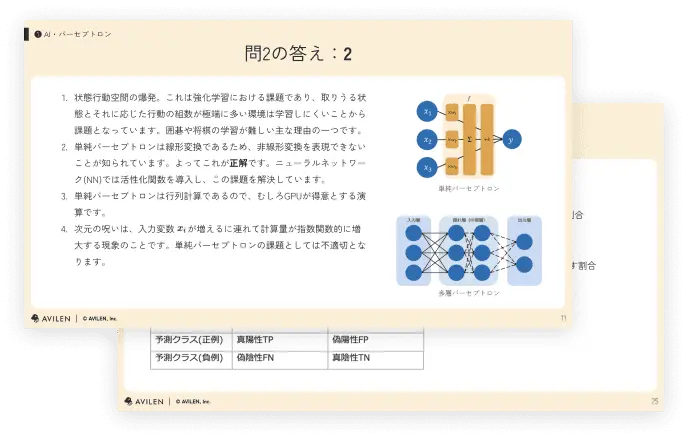
問2. パーセプトロン
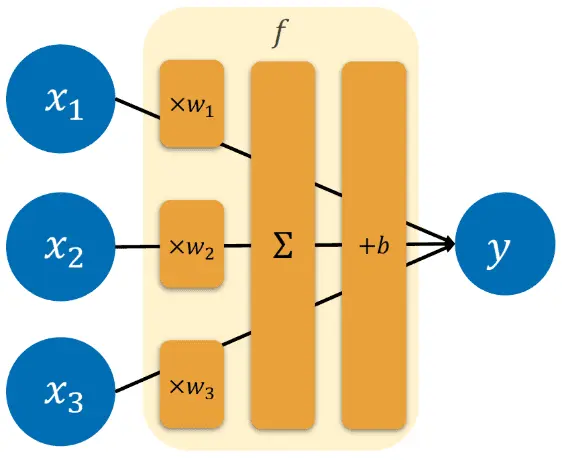
ディープラーニングの原点として知られている単純パーセプトロンは、下図のような構造を持つ。この単純パーセプトロンの課題として、最も適切なものを次の選択肢から選べ。
- 状態行動空間が膨大となる
- 非線形変換を表現できない
- GPUによる高速演算が難しい
- 次元の呪いが生じやすい
機械学習
問3. 教師あり/なし学習・強化学習
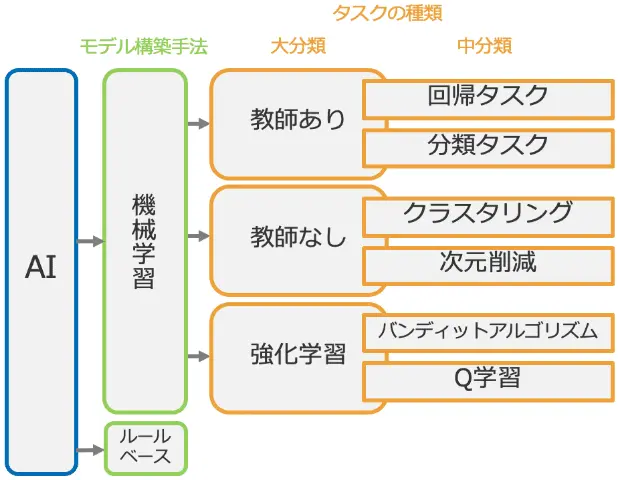
AIは下図のように分類される。
ここではタスクの種類(中分類)に注目して、特に教師なし学習のクラスタリングの例として適切なものを次の文章から1つ選べ。
- 車メーカーが次のプロダクトを考えるため、過去のヒット製品の属性をk-meansにより解析した。結果として、家庭用ミニバン、荷物を多く運ぶワンボックス、モテるSUVの3つにグルーピングされた。
- 生徒の学力特性を把握するため、9科目のテストの点数に対して主成分分析を行った。その結果、有用な主成分は2つあり、国数理英で養う論理的思考力と、技術・美術・音楽で養うクリエイティブ性で生徒の学力を測定できることがわかった。
- 与信審査において、各人の属性を説明変数として一般化線形回帰モデルで信用スコアを学習した。その結果、回帰係数を観察したところ、安定した収入が得られている職業であるかが予測に寄与することがわかった。
- CNNモデルを用いて、犬と猫の画像分類タスクを学習した。CNNにおけるフィルターを可視化したところ、ヒゲの有無を検出するフィルターが分類に寄与することがわかった。
問4. バイアスとバリアンス・正則化
次のバイアス・バリアンスに関する文章のうち、誤っているものを選べ。
- バイアスとバリアンスはトレードオフ(一方が小さくなれば他方は大きくなる)の関係にある。
- バリアンスとは、モデルの予測値の分散(散らばり)であり、この値が⼤きければモデルは過学習していると言える。
- バイアスとは、データ間に見られるノイズであり、機械学習手法で抑えることはできない。
- 正則化は、学習中にパラメータ(重み)やモデルに制約をかけることで、バリアンスを抑え、過学習を防ぐ効果がある。
問5. モデル検証方法とデータリーク
予測モデルの精度は正しく評価されなければならない。そのためには、データの準備段階において、その分割方法に注意を払う必要がある。次のデータ分割手法に関する具体例のうち、目的と手法が一貫していないものはどれか。
- スポーツジムの顧客のマスタデータを用いて、退会者予測をしたい。目的変数は「半年後に辞める」/「辞めない」の2クラスであり、また説明変数には”年齢層ごとの目的変数クラスの割合”を加えている。このとき、ホールドアウト検証時には、検証用データを除外した学習データの目的変数のみを使って特徴量を作り直した。
- 時系列データに対して、単純なクロスバリデーションを行うとき、未来の情報をリークして過去の目的変数を予測する事態となる。現実に実装する際に、未来の情報を持ち得ないため、時系列に沿ってデータを分割し、学習データと検証データの時間的な関係性を保ちながらクロスバリデーションを行った。
- 卓球の世界大会の対戦データを用いて、勝敗予測をしたい。対戦カード2選手のそれぞれの名前は、その試合を表す重要な説明変数となるのでマスクなどの前処理はせず、そのままモデルに利用した。その結果、学習データに対する正解率が100%であったのでクロスバリデーションを行う必要がないと判断した。
- 多値分類タスクにおけるクロスバリデーションでは、各foldの各クラスの割合にムラが生じないように、層化抽出を行なった。ここで、層化抽出とは、テストデータに含まれる各クラスの割合は、学習データに含まれる各クラスの割合とほぼ同じであるという仮定に基づき、各foldの各クラスの割合を均等にする手法である。
問6. 評価指標
次の文章は機械学習における評価指標を説明したものである。1-4のうち誤っているものを選べ。
- 絶対値平均MAEは、平均二乗誤差RMSEに比べて、大きな誤差を少なく見積もることができるため、目的変数の外れ値に影響を受けにくい。
- 回帰タスクにおいて、横軸に正解ラベルを、縦軸にモデルの予測値をプロットしたグラフの相関係数が0.95であった。正解ラベルと予測値には強い相関があるので、このモデルの精度は信頼に足るといえる。
- 二値分類タスクの評価指標として用いられる、適合率(precision)は、モデルが正例と予測したもののうち実データではどれだけ適合しているかを表す割合であり、再現率(recall)は、実データで正例であるもののうち、モデルが正例と予測してどれだけ回収できたかを表す割合であるため、それぞれトレードオフの関係にある。
- 予測確率を正例と判別する閾値を徐々に変化させていったときに偽陽性率と真陽性率の関係をプロットしたグラフをROC曲線という。この曲線の下側の領域の面積はAUCと呼ばれ、この値が高いほどトレードオフに対応したモデルであるといえる。
問7. アンサンブル学習
次の文章を読み、空欄に最もよく当てはまる選択肢を選べ。
アンサンブル学習とは、複数の弱学習器を統合して一つの高精度な学習器を構築し、汎化性能を高める学習方法である。このアンサブル学習の一つである(ア)は、学習データから復元抽出した複数のデータセットに対して、それぞれの弱学習器を構築し、それらの学習結果を統合したものを最終的な結果とする。データセットに多様性を持たせることで(イ)効果がある。この代表的なモデルである(ウ)は、弱学習器に決定木を用いたモデルである。
(ア)の選択肢
- バギング
- ブートストラップ
- ブースティング
- スタッキング
(イ)の選択肢
- モデルの予測値のバリアンスを下げる
- モデルの予測値と正解ラベルとのバイアスを下げる
- 共変量シフトを減少させる
- 重みをスパースな解にする
(ウ)の選択肢
- ランダムフォレスト
- SVM
- 勾配ブースティング木
- AdaBoost
ディープラーニング
問8. MLP・誤差逆伝播・最適化
次の文章を読み、空欄に最もよく当てはまる選択肢を選べ。
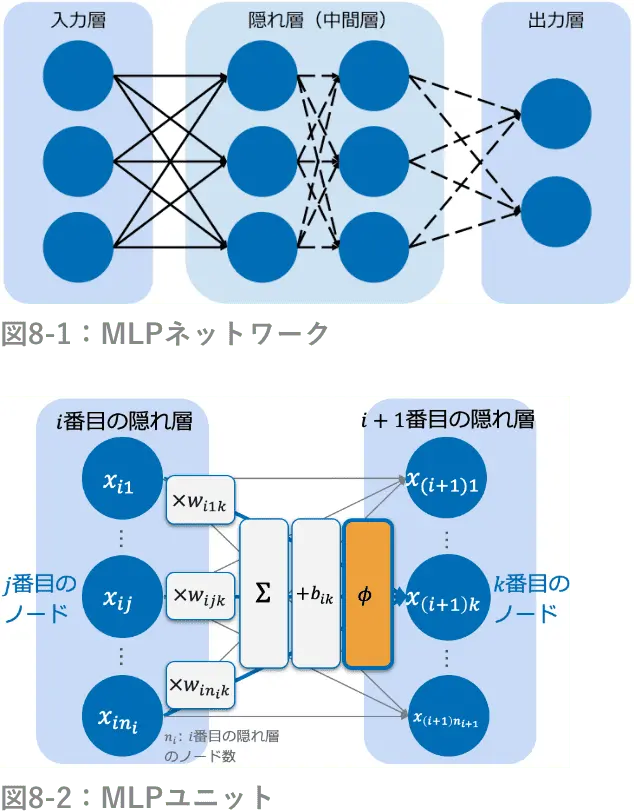
ニューラルネットワーク(以下NN)における順伝播は以下の図のように表される。ただし、ここでは重みパラメータを(ア)として示している。NNは入力層と出力層、その間にある隠れ層で構成される。
また近年では、隠れ層の活性化関数として、(イ)を解決できるという理由から、ReLU関数が主流になっている。 NNの目標は、モデルの予測値を正解ラベル(目的変数)の値に近づけることであり、その差を表す誤差関数を最小化する手法がとられている。NNでは、この最小化アルゴリズムの一つに勾配降下法が使われる。さらにその一種として、学習データの一部を毎度ランダムに抽出し、それに対する損失関数を重み更新ごとに確率的に変える(ウ)がある。 また、出力層に近い層から順に連鎖的に算出した勾配をもとに各重みパラメータを更新していく学習法は(エ)と呼ばれる。
- (ア)ω (イ)勾配爆発問題 (ウ)確率的勾配降下法 (エ)連鎖律
- (ア)ω (イ)勾配消失問題 (ウ)確率的勾配降下法 (エ)誤差逆伝播法
- (ア)b(イ)勾配爆発問題 (ウ)最急降下法 (エ)連鎖律
- (ア)b(イ)勾配消失問題 (ウ)最急降下法 (エ)誤差逆伝播法
問9. ディープラーニング学習の工夫
ディープラーニング(DL)の学習における諸処の課題を解決する方法として、不適切なものを選べ。
- 過学習を防ぐ手法の一つに、一定の割合のノードをランダムに消去して学習を行うドロップアウトがある。ドロップアウトを用いて学習したモデルは、学習時に消去しなかったノードを用いて推論が行われるため、どのノードで学習したのかを保存しておく必要がある。
- 過学習を防ぐ手法の一つに、学習を早めに打ち切る早期終了(early stopping)がある。損失関数の最適化を早めに終了させることは、重みパラメータを制約することと同等とみなせるため、早期終了はノルムペナルティと同等の正則化効果があると言われている。
- 各層の⼊⼒時の分布が学習中に変化することで、学習が困難になる現象(共変量シフト)を解決するために、バッチ正規化が用いられる。
- 全ての学習データをまとめて学習するバッチ処理では、データサイズが膨大であれば、DLの計算量が膨れ上がり重み更新が進みづらい課題がある。そこでミニバッチ学習は、学習データをいくつかのグループに分けて学習を行うことで、重み更新の頻度を細かくし学習の収束を早くさせた。
問10. CNN
CNNとは畳み込み処理を含むニューラルネットワークであり、画像処理分野へ応用される技術として有名である。次のCNNに関する文章のうち、最も不適切なものを選べ。
- 畳み込み処理とは、カーネル(フィルター)を用いて画像内の特徴を抽出する技術であり、CNN以前の畳み込み処理は人工的に設計したカーネルを用いていた。しかしCNNにおける畳み込み処理はバックプロパゲーションによりカーネル中の数値を学習することで、より高精度な特徴抽出が可能となった。
- 画像や特徴マップなどの入力サイズを圧縮する手法としてプーリングと呼ばれる処理がある。この処理は、学習させるパラメータを必要とせずとも、画像内の物体の色やトーンのわずかな違いに対して不変性をもつ効果がある。
- 2014年VGGが提案された論文では、3×3のカーネルのみの畳み込み処理を何回も繰り返すことで、パラメータ数を抑えながら、大きなカーネルサイズと同じ受容野をカバーできることが示された。
- VGGの抱える課題である「多層化による勾配消失問題」を解決した技術が、2015年ResNetの論文で提案されたスキップ構造(ジャンプ構造, skip connection)である。ResNetは、その構成要素である各Residual Blockが、その入力と出力の差を学習することにより、152層に及ぶ超多層化を実現した。
問11. RNN・LSTM
次の文章を読み、空欄に最もよく当てはまる選択肢を選べ。
テキストのような時系列を持つデータから重要な特徴を抽出するためには、入力される順序の情報を保持する必要がある。つまり「過去の入力」や「現在の入力」という概念をモデルに組み込む必要がある。そこで考えられたニューラルネットワーク(以下、NN)がリカレントニューラルネットワーク(以下、RNN)である(図11-1)。
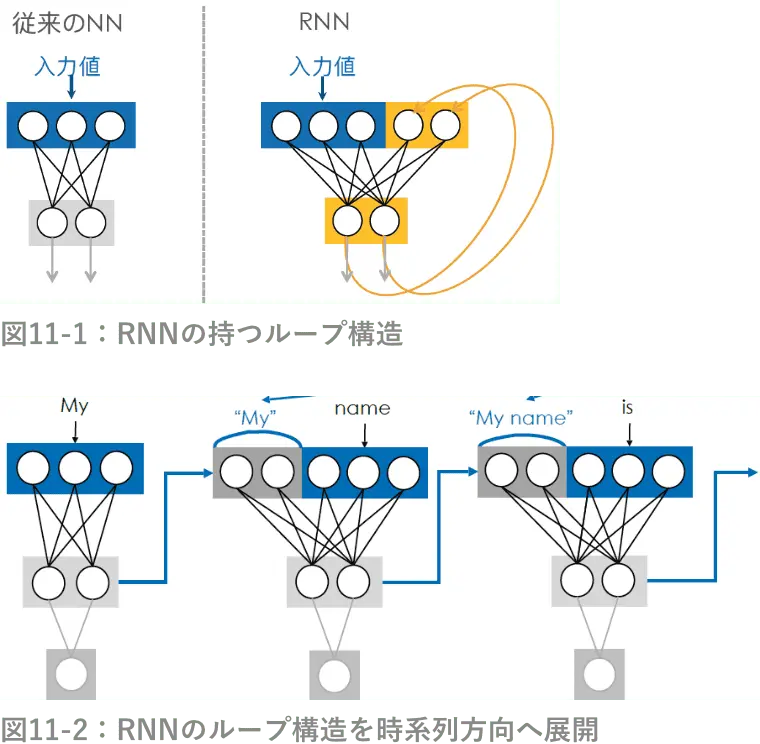
図11-1(右)のRNNはループ構造を持つことから、誤差逆伝播法が適用できない。したがって図11-2のように、RNNの持つループ構造を時系列方向へ展開させることで、時系列方向に沿って誤差逆伝播を適用することが可能となる。この手法の中で、逆伝播の途中で断絶することなく適用することを(ア)という。 また、時系列データを扱う上での固有の問題として、“現時点では関係性が少なくても、将来的には関係性がある”という特徴が入力された場合に、その入力に対する重みを小さくすべきであると同時に、重みを大きくしなくてはいけない、といった矛盾が生じてしまう。これを(イ)という。 この(イ)を解決するためにLSTM(Long Short-Term Memory)モデルが考えられた。LSTMは(ウ)と呼ばれる情報を記憶する構造と、3つのゲート構造を持つことで、重要な情報は保持し続け、不必要な情報は適当なタイミングで削除されることが可能となり、(イ)の解決につながった。
- (ア)通時的誤差逆伝播(BPTT) (イ)入力重み衝突 (ウ)CEC(Constant Error Carousel)
- (ア)通時的誤差逆伝播(BPTT) (イ)出力重み衝突 (ウ)GRU(Gated Recurrent Unit)
- (ア)Truncated BPTT (イ)入力重み衝突 (ウ)CEC(Constant Error Carousel)
- (ア)Truncated BPTT (イ)出力重み衝突 (ウ)GRU(Gated Recurrent Unit)
問12. 画像処理分野
次の文章を読み、空欄に最もよく当てはまる選択肢を選べ。
近年、画像処理分野においてディープラーニングの活躍が目覚ましい。その中でもセグメンテーションとは(ア)技術であり、医療画像診断や自動運転への応用として注目されている。セグメンテーションの代表的なモデルとして(イ)があ近年、画像処理分野においてディープラーニングの活躍が目覚ましい。その中でもセグメンテーションとは(ア)技術であり、医療画像診断や自動運転への応用として注目されている。セグメンテーションの代表的なモデルとして(イ)がある。(イ)は、逆畳み込み処理を導入してネットワークの全てを畳み込み処理に置き換えていることや、shortcut接続によって空間情報を補完していることが重要な特徴である。 一方で物体検出とは(ウ)技術であり、自動運転技術や監視カメラの解析技術として注目されている。その代表的なモデルである(エ)は、それまでの物体検出の常識を覆した。(エ)以前の物体検出モデルでは、物体がありそうな場所を検出するフェーズを経てから、その物体が何かを識別するフェーズに移るように、段階的なアーキテクチャであった。しかし(エ)は、入力画像をN×N(論文中はN=7)にセル分割することで、検出フェーズと識別フェーズを同時に行うことを可能にし、認識速度をそれまでの10〜20倍にした。
(ア) (ウ)の選択肢
- エンコーダデーコーダアーキテクチャによって画像を生成する
- 画像中の物体をピクセルごとに領域予測やクラス分類する
- その画像自体が何を示すのかをクラス分類する
- 画像中の物体やその位置を矩形の領域を用いて囲い特定する
(イ) (エ)の選択肢
- SegNet
- U-Net
- Faster R-CNN
- YOLO
問13. 自然言語処理分野
自然言語処理とは、自然言語(人がコミュニーケーションに用いる言語)をコンピューターが解析しやすいように数値化する技術である。近年では、特にAttentionを用いたモデルの発展は目覚ましい。次のAttentionに関連する文章のうち、誤っているものはどれか。
- 機械翻訳に応用されるSeq2Seqのモデルアーキテクチャはエンコーダ(入力文を処理するモデル)とデコーダ(出力文を予測するモデル)に分かれ、Attentionとは、デコーダがエンコーダの出力情報を参照・利用する機構のことである。
- TransformerはAttentionのみを使用したモデルであり、従来のRNN/LSTMを使用したモデルに比べてGPUを有効活用できるなど利点が多い。
- OpenAI GPTはTransformerの一部を単語モデルへ応用したアーキテクチャであるが、時系列的に未来の情報を参照できないなど課題がある。
- BERTは双方向Transformerモデルとして知られ、その事前学習に特徴がある。中でも、Masked Language Model(MLM)は、2文が渡され、連続した文かどうか判定するタスクとして有名である。
問14. 音声処理分野
14-1. 空欄に最もよく当てはまる選択肢を選べ。
近年、音声処理分野におけるディープラーニングは、スマートスピーカーやスマホ向けのAIアシスタントなどへ応用され、その音声認識や音声合成の精度に注目が集まる。そこで近年の音声処理技術を理解するために、音声処理分野の基礎知識を習得することは重要である。 ここでは人が発する音声の音響的な特徴量を抽出することを考える。音声のような波形信号から周波数成分ごとの振幅(強度)を抽出するスペクトル解析に用いられる変換手法を(ア)という。(ア)によって得られたスペクトルには、いくつかのピークが見られ、それらのピークに対応する周波数は(イ)と呼ばれる。たとえば各母音は、一般的に第一(イ)と第二(イ)で表現されることが知られている。しかし、(イ)のみの情報だけでは、音声スペクトルの微細構造を再構築する上で不十分であり、これに加えて、周波数全域のスペクトルの概形を抽出するためにケプストラム分析などが用いられる。 2016年当初、このような人の音声を再現する解析手法・モデルには多くの課題があり、特にゆらぎ成分をいかにモデル化するかが鍵であった。2016年9月、CNNを用いた時間波形の確率的生成モデルであるWaveNetが開発された。音声波形にゆらぎを持たせるための工夫のほか、様々な工夫により自然な音声を生成できる。
(ア)の選択肢
- 正規化
- 量子化
- テイラー展開
- フーリエ変換
(イ)の選択肢
- 母音周波数
- フォルマント周波数
- スペクトル包絡
- パルス
14-2. 次のうちWaveNetの工夫として当てはまらないものはどれか。
- inception module
- Gated Activation Units
- Dilated Causal Convolutions
- Residual & Skip Connections
問15. 深層強化学習・ロボティクス
強化学習とは、ある一定のルールの中で複雑な自由度を持つシステムやゲームの制御や次の一手を定めるための学習である。深層強化学習とは、この学習に深層学習(ディープラーニング)を導入したものである。 その代表例としてAlphaGo Zeroがある。人間の経験(棋譜)を必要とせず、一人二役のシミュレーション(自己対局)を何度も行うことで学習データを収集し、そのデータをDNNに入力して「現在の盤面における最適手」や「現在の盤面からの勝率」を予測し、AlphaGoよりシンプルなアーキテクチャで囲碁の勝率を高めた。
【問】次の文章は深層強化学習を応用した一例である。目的に沿った環境設定として適切なものを選択肢より選べ。
目的: 腕型ロボットの掌握精度を高める
状態:( ア )
行動:( イ )を変える
報酬:( ウ )
- 各関節のモーターの回転方向と量
- 物体を握ってから落とすまでの時間
- ロボットに取り付けた各種センサーの数値
問16. AutoML
Auto MLとは、高精度の機械学習モデルの構築を自動化するシステムである。2018年1月、Google社はCloud Auto MLを公開した。その背景にはNeural Architecture Search(NAS)と呼ばれる、モデルのアーキテクチャそのものを最適化する理論がある。次のNASに関する文章のうち、誤っているものを選べ。
- NASは、Controller RNNが設計したハイパーパラメータを用いて、Child Networkが対象のタスクを学習し、その検証データに対するAccuracyをController RNNの報酬として、Controller RNNを更新する。このようにNASは強化学習のアーキテクチャを応用している。
- NASのController RNNの更新には、Q学習のような価値関数ベースの手法が使われている。
- NASNetは、そのChild NetworkをCNNに限定し、いくつかの畳み込み層やプーリング処理をまとめたCNNセルをController RNNの探索空間とすることで、NASよりパラメータ探索を効率化した。
- Efficient NAS(ENAS)は、 Controller RNNによるアーキテクチャ探索に有向非巡回グラフを活用し、NASより効率的なパラメータ探索が可能となった。
問17. XAI (Explainable AI)
DLの強みの一つに、特徴量抽出・作成の自動化がある。一方で、その推論の過程がブラックボックス化され、その特徴量の抽出に至った根拠を説明できないといった課題がある。近年、AIが社会に実装されていく中で、XAI(説明可能なAI)が注目されている。次のXAIに関する文章のうち、誤っているものを選べ。
- 入力を表形式データとするモデルの出力の根拠を提示する技術にLIMEやSHAPなどがある。これら技術を使う際に、なるべく元データの状態を保つ必要があるため、カテゴリカル変数をone-hot表現にせずに扱った。
- LIMEは、説明の欲しいサンプルに近いデータをランダムに生成し、元のモデルを用いてそれらデータから分類結果を推論する。この分類結果を表現できる、よりシンプルな線形モデルの係数から推論に有用な特徴量を特定する。
- SHAPはゲーム理論のShapley値の計算に基づいて各説明変数の推論結果への寄与度を求める。
- CAMは最終畳み込み層の特徴マップにGlobal Average Pooling(GAP)の処理を施したとき、特徴マップの可視化ができるという仮定の上で提案されたが、Grad-CAMでは、GAPの代わりに最終畳み込み層の特徴マップの勾配を用いることができることを示し、これによってどのようなモデルアーキテクチャであっても特徴マップの可視化が可能となった。
法律・社会
問18. AIと著作権
学習済みモデルの精度向上などを目指した「派生モデル」や「蒸留モデル」。いずれのモデルにおいても、既存のモデルを用いて作成されるという特徴があるため、著作権侵害にあたるのか否かの議論が盛んに行われる。次の既存モデルを応用したモデルに関する文章のうち、誤っているものを選べ。
- 著作権者は、自己が著作権を有する著作物を自分で利用するだけでなく、他人に対し、その利用を許諾することができる。許諾を得た者は、その許諾に係る利用方法及び条件の範囲内において、その許諾に係る著作物を利用することができる。
- モデルを所有する人が、その精度を高めるために学習済みパラメータを改変することは、機能を向上させるための翻案といえ、必要と認められる範囲の翻案にあたり違法ではないと考えられる。
- プログラム部分は変えずに、加工データを追加することで学習させた結果、学習済みパラメータ部分が改変した場合には、学習済みパラメータにおける「情報選択や体系的構成」の創作性がある部分を改変したことにはならないため違法でないと考えられる。
- 蒸留モデルとは、既存の学習済みモデルの入力値と出力値を利用して、そこから新たなプログラムを作成することで得られたモデルであるため、複製権を侵害していると考えられる。
問19. 自動運転と法整備
2020年4月、日本は世界に先駆けて、自動運転レベル3の社会実装に向け、道路交通法と道路運送車両法が改正・施行された。道路交通法はドライバーが守るべきルールを定めた法律であり、道路運送車両法は道路を走行する車両が満たすべき技術基準を定めた法律である。次の自動運転における法整備に関する文章のうち、誤っているものを選べ。
- 自動運行装置による走行であっても、「運転」と定義され、その時のドライバーは道路交通法上定められたドライバーの安全運転義務を果たさなければならない。
- 自動運行装置のセンサーが作動しなくなってしまった際に、車両からの警告を受けたドライバーは直ちに通常の運転に戻る必要がある。
- 自動運行装置を使用したドライバーは、たとえば天候が悪化して自動運行装置の使用条件を満たさなくなった際に、直ちに通常の運転に戻れるように、いかなる時もスマホの使用や車載テレビの視聴は許されない。
- 道路運送車両法の改正により、プログラムの改変による改造等に関する許可制度が定められた。これによって、電気通信回線を使用することで、保安基準に適合しなくなるおそれのある自動運行装置のソフトウェアアップデートを行う場合に、国土交通大臣の許可を受けなければならない。
問20. 生成モデルと個人情報保護
2017年、有名人の顔をアダルト動画と合成したディープフェイクポルノがネット上で拡散された。ディープフェイクとは、ディープラーニング技術を応用した合成メディアのことである。この深層生成モデルを応用した技術は、名誉毀損、脅迫などに悪用されかねない。次の文章のうち、ディープフェイク対策(2020年12月現在)として誤っているものを選べ。
- 人間のまばたきパターンは、体調、認知活動、生物学的要因、情報処理レベルに応じて大幅に変化することが知られている。Deep Visionは、短い時間の間にまばたきが連続して繰り返された際の”周期”,”繰り返し回数”,”経過時間”に基づいてディープフェイクを検知できる。
- ディープフェイクビデオでは、フレーム間の動きの不整合が生じる可能性がある。オプティカルフロー(物体の動きをベクトルで表したもの)の推定により、ディープフェイクを検知する手法の提案がなされている。
- アーティファクト(画像加工の証拠を検出する手法)の一種であり、GANsが生成する画像に内在する特定のフィンガープリントを検出する手法の提案がなされている。
- 一般的に、データ圧縮やサイズ変更、ノイズなどによって品質が低下した動画であるほど、ディープフェイク検出モデルの精度は上がりやすい傾向にある。



お疲れ様でした!
答えをメモし終わったら、下のボタンから解答・解説をダウンロードして、スキル判定をしましょう。不足している知識を補い、合格へ一歩近づくための勉強方法も紹介します。

よくあるご質問
- Q
G検定とはどのような資格ですか?

一般社団法人日本ディープラーニング協会(JDLA)が主催している資格試験で、「ディープラーニングの基礎知識を有し、適切な活用方針を決定して、事業活用する能力や知識を有しているか」を検定します。
デジタルリテラシー協議会は、ビジネスパーソンが獲得すべきデジタルリテラシー「Di-Lite」のうち、人工知能(AI)・ディープラーニング領域を学習できる試験として位置付けています。 - Q
G検定の対策を効率的に進める方法はありますか?
- Q
G検定に合格した後、ネクストステップで学習すべき資格はありますか?
さらにデジタルリテラシーを学びたい場合は「DS検定」、AIエンジニアリングを学びたい場合は「E資格」がおすすめです。
DS検定は、一般社団法人データサイエンティスト協会が主催している資格試験で、「アシスタント・データサイエンティスト(見習いレベル:★)と数理・データサイエンス教育強化拠点コンソーシアムが公開している数理・データサイエンス・AI(リテラシーレベル)におけるモデルカリキュラムを総合し、実務能力と知識を有すること」を検定します。
E資格は、G検定同様JDLAが主催している資格試験で、「ディープラーニングの理論を理解し、適切な手法を選択して実装する能力や知識を有しているか」を認定します。
AVILENでは、「全人類がわかるDS検定対策講座」、「全人類がわかるE資格講座」をご提供しております。ご興味のある方は、ご確認ください。