


E資格スキルチェック
テストとは
このテストは、E資格講座*でディープラーニング(深層学習)を学ぶ上での前提知識である
数学・統計学・Python・機械学習のスキルが、どの程度身についているかチェックするための簡易試験です。
問題を解いたら自分の答えをメモしていただき、解答を見て自己採点を行ってください。
合計点数からあなたの現在の知識レベルを判定し、おすすめの試験対策方法が分かります。
*E資格とは、日本ディープラーニング協会(JDLA)が主催する、AIエンジニアの実装技術を測る資格です。
E資格を受験するには、JDLA認定プログラムを受講し、修了する必要があります。
問題(全18問)
数学・統計分野
問1. 線形代数 (行列の固有値の算出)
- 5
- 7
- 9
- 11
問2. 微分 (シグモイド関数の微分)
問3. 確率 (確率変数の性質)
問4. 統計 (ポアソン分布)
- 全国の交差点における死亡事故の発生件数
- サイコロを投げたときに6の目が出るまでにかかる回数
- コインを投げたときに表が出る回数
- 自宅にある家電製品の故障数
問5. 情報理論 (KLダイバージェンス)
Python分野
問6. 条件分岐

- (あ) if var > 0 : (い) elseif var < 0 : (う) else :
- (あ) if var < 0 : (い) elseif var > 0 : (う) else :
- (あ) if var < 0 : (い) elif var > 0 : (う) else :
- (あ) if var > 0 : (い) elif var < 0 : (う) else :
問7. 関数の実装 (range)
- [ I for I in range(100) if I % 2 = 0 ]
- [ I for I in range(100) if I % 2 == 0 ]
- [ I for I in range(101) if I % 2 = 0 ]
- [ I for I in range(101) if I % 2 == 0 ]
問8. クラス(インスタンス/標準出力)

- A is created だけ
- B is created だけ
- 何も表示されない
- A is created と B is created の両方
問9. Pandasによるデータ抽出

- df.iloc([10:101, [“Age”, “Sex”]])
- df.iloc[10:100, [“Age”, “Sex”]]
- df.loc([10:101, [“Age”, “Sex”]])
- df.loc[10:100, [“Age”, “Sex”]]
問10. データフレームの並び替え
・Genderが分かれた状態でM→Fの順で並んだだけでなく、それぞれデータはHeightが高い順に出力された。
・Heightが同じ場合は、Weightが重い順に並んでいる。
実行したコードとして考えられるものを選択せよ。
- SD.sort_values([“Gender”, “Height”,”Weight”], ascending = [False, False, False])
- SD.sort_values([“Gender”, “Height”,”Weight”], ascending = [True, False, False])
- SD.sort_values([“Gender”, “Height”,”Weight”], ascending = [False, True, True])
- SD.sort_values([“Gender”, “Height”,”Weight”], ascending = [True, True, True])
問11. Matplotlib
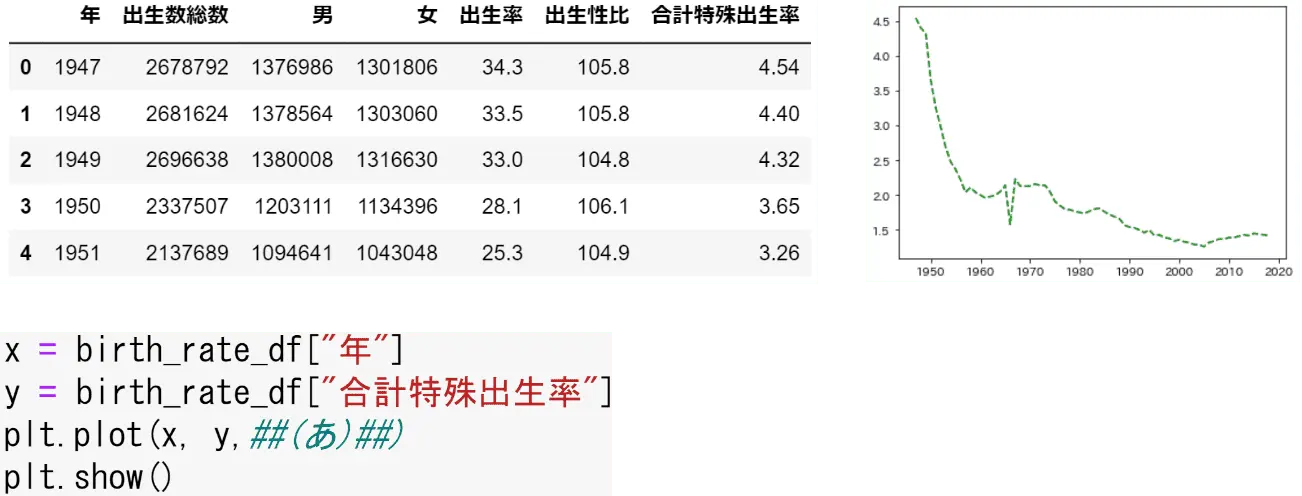
- color=‘g’, linestyle=‘dashed’
- color=‘c’, linestyle=‘solid’
- color=‘m’, linestyle=‘dotted’
- color=‘y’, linestyle=‘dashdot’
問12. NumPy

- shape(3, 2)
- reshape(3, 2)
- reshape(2, 3)
- sum()
機械学習分野
問13. 回帰モデル
- データ中において類似的性質を有する集合を見出す。
- 目的変数を複数の説明変数を用いて予測する。
- 入力に応じて二種類に判別する。例えば入力をx、0および1で表現される二値変数をyとすると、xからyを推定する。
- 入力に応じて有限個のクラスに分類する。
問14. ロジスティック回帰
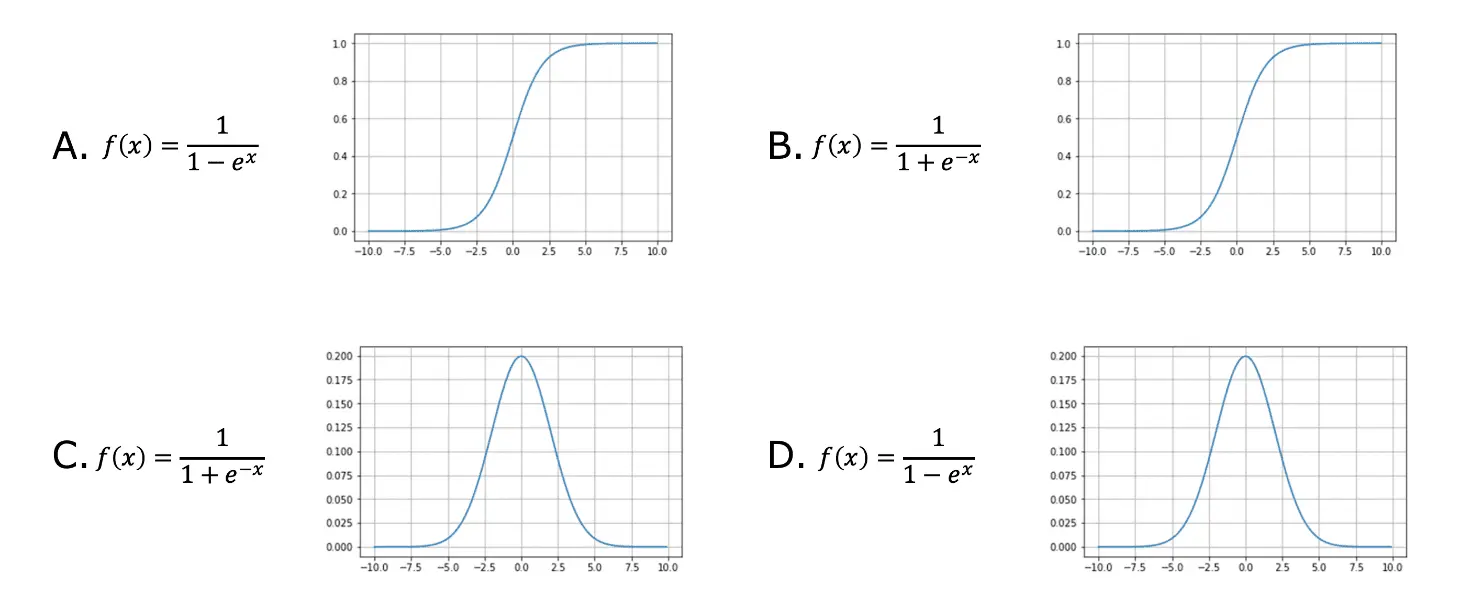
問15. holdout
- モデルに全データのXとyをそれぞれ入力し、作成したモデルに検証用データのXを入力する。その後、出力された答えと検証用データのyで答え合わせを行う。
- モデルに検証用データのXとyをそれぞれ入力し、作成したモデルに学習用データのXを入力する。その後、出力された答えと検証用データのyで答え合わせを行う。
- モデルに学習用データのXとyをそれぞれ入力し、作成したモデルに全データのXを入力する。その後、出力された答えと全データのyで答え合わせを行う。
- モデルに学習用データのXとyをそれぞれ入力し、作成したモデルに検証用データのXを入力する。その後、出力された答えと検証用データのyで答え合わせを行う。
問16. パラメータ探索
- グリッドサーチはハイパーパラメータの候補値を指定して、それぞれのパラメータで学習を行い、テストデータセットに対する予測が最も良い値を選択する手法である。
- ランダムサーチはハイパーパラメータの候補値ではなく、探索の対象とするハイパーパラメータ自体をランダムに決定し学習を行うことによって、テストデータセットに対する予測を徐々に向上させる手法である。
- グリッドサーチは探索するパラメータの候補値をランダムサーチよりも把握しやすい一方、組み合わせの数だけ探索点の数が膨大になるというデメリットがある。
- ランダムサーチはグリッドサーチよりも計算時間が短く済むが、最適な組み合わせにたどり着かないという可能性がある。
問17. kNN
- 分類手法の一つであり、与えられたデータ周りのk個のデータから、多数決によってデータが属するクラスを分類する。
- 評価時よりも訓練時に計算量が多く、パラメトリック手法の一種と呼ぶことができる。
- 計算量が多く、それを回避する手段として削除型、圧縮型などのkNN法も存在する。
- k=1のとき、各データ間のボロノイ境界が、判別境界になる。
問18. PCA

- np.argsort(self.eigen_vecs)
- np.argsort(self.eigen_vecs)[::-1]
- np.argsort(self.eigen_vals)
- np.argsort(self.eigen_vals)[::-1]



お疲れ様でした!
答えをメモし終わったら、下のボタンから解答・解説をダウンロードして、スキル判定をしましょう。不足している知識を補い、合格へ一歩近づくための勉強方法も紹介します。
よくあるご質問
- Q
E資格とはどのような資格ですか?

一般社団法人日本ディープラーニング協会(JDLA)が主催している資格試験で、「ディープラーニングの理論を理解し、適切な手法を選択して実装する能力や知識を有しているか」を認定します。
試験では、「応用数学」、「機械学習」、「深層学習」、「開発・運用環境」の分野が出題されます。
E資格には受験資格が設定されており、「JDLA認定プログラム」を試験日の過去2年以内に修了することが必要です。
AVILENでは、JDLA認定プログラムとして「全人類がわかるE資格講座」をご提供しています。 - Q
E資格講座の詳細がわかるサービス資料やデモ動画はありますか?
講座の詳細(講座の流れ・料金体系・申し込み方法)をまとめた資料とトライアル用の講座動画をご用意しています。ご希望の方は、こちらの資料請求フォームからお申し込みください。
- Q
スキルチェックテストの結果、前提知識に不安があります。効率的に学習するにはどうしたらよいですか?
AVILENが提供する「全人類がわかる機械学習講座」の受講をおすすめします。
この講座は、機械学習の基本的な「分析タスク」と「モデル精度評価」のスキル獲得を目指し、「数理統計」「Pythonプログラミング」「機械学習モデル構築」を一気通貫で学習します。
数学・統計・Pythonプログラミングを、機械学習エンジニアリングに関連付けて効率的に学習できる点がメリットです。
本講座を修了することで、E資格講座の受講に必要な前提知識を獲得することができます。