ベイズ統計の区間推定を解説
目次
頻度論とベイズ論の区間推定の違い
頻度論とベイズ論の区間推定について解説します。
頻度論における区間推定の考え方
頻度論における区間推定の考え方について説明します。
母分散既知の正規分布に従う標本からデータをn個取ってきたとき、母平均に関する区間推定は、有意水準をとすると、
と表せられます。このような区間は信頼区間と呼ばれています。
頻度論はパラメータを定数、データを確率変数として考えるので、上記の式を書き直すと、
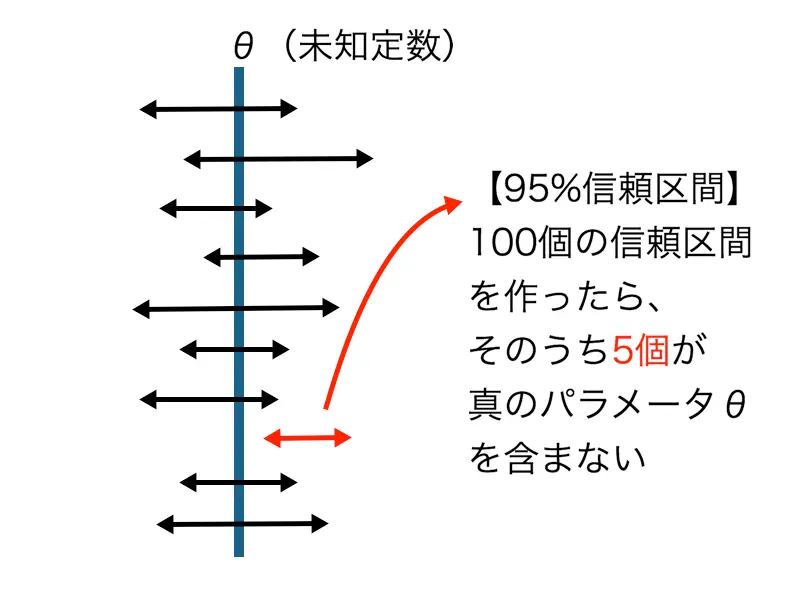
となり、区間が変数となることがわかります。つまり、得られるデータによって区間が変動するのです。
よって、95%信頼区間は「データを得て100個の信頼区間を作ったとき、95個の信頼区間が真のパラメータを含む」と解釈されます。
ベイズ論における区間推定の考え方
ベイズ統計ではパラメータを確率変数、データを定数として考えるので、上記の式は、
と書き換えられ、区間が定数となります。
つまりベイズ統計の区間推定では、真のパラメータがその区間に存在する確率そのものが得られます。このような区間は信用区間(確信区間)と呼ばれています。
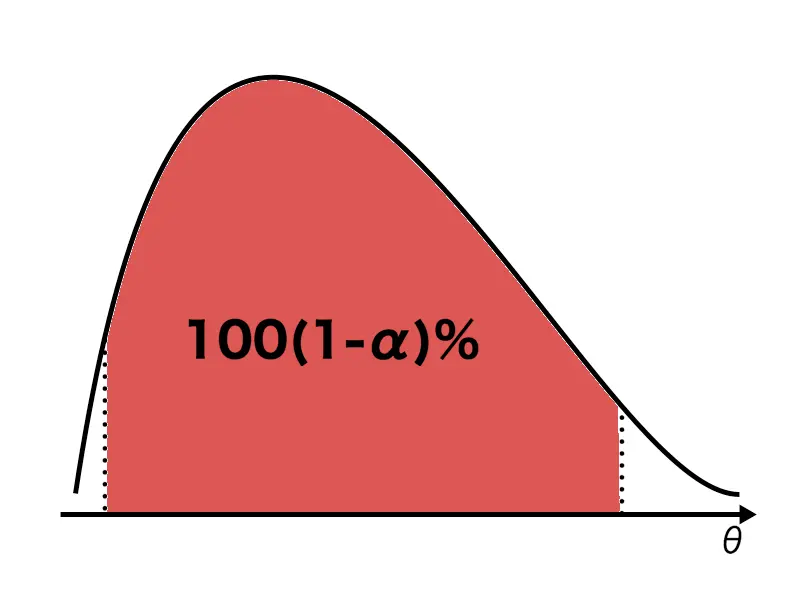
確率変数の分布は事後分布によって与えられているので、%信用区間は以下のように与えられます。
信頼区間と信用区間の違い
信頼区間と信用区間の違いを例題を通して解説します。
【例題】
日本人男性全体の平均身長を調べたい。日本人男性全員を調査することは不可能なので、無作為に標本抽出をした。このデータから日本人男性全体の身長を推測したい。
⑴得られた標本から作成された95%信頼区間がであった。この解釈を述べよ。
⑵得られた標本から作成された95%信用区間がであった。この解釈を述べよ。
⑴今回作成されたという区間内に真の平均身長を含む確率は95%である。「真の平均身長が165cm〜175cmである確率」などは存在せず、あくまでもこの区間内に真値を含むか否かでしか測れない。
⑵真の平均身長を確率変数とみなす。このとき、確率変数がの値をとる確率が95%である。「真の平均身長が165cm〜175cmである確率」などが存在する。得られたデータから、真の平均身長をとる値を確率的に推測できる。
信用区間(確信区間)の定義
信用区間の定義は以下のようになります。
の区間とは、
を満たすような部分集合である。
ただし、は連続型の確率変数
信用区間の種類
ベイズ統計の信用区間は、等裾事後信用区間と最高事後密度信用区間(HPD区間)の2つが有名です。
以下、、、をそれぞれ点、点として説明していきます。
等裾事後信用区間
と言うように、を選んだとき、得られる信用区間を等裾事後信用区間と言います。等裾事後信用区間は以下のようになります。つまり、等裾事後信用区間は両裾を等しく切り捨てるような形になります。
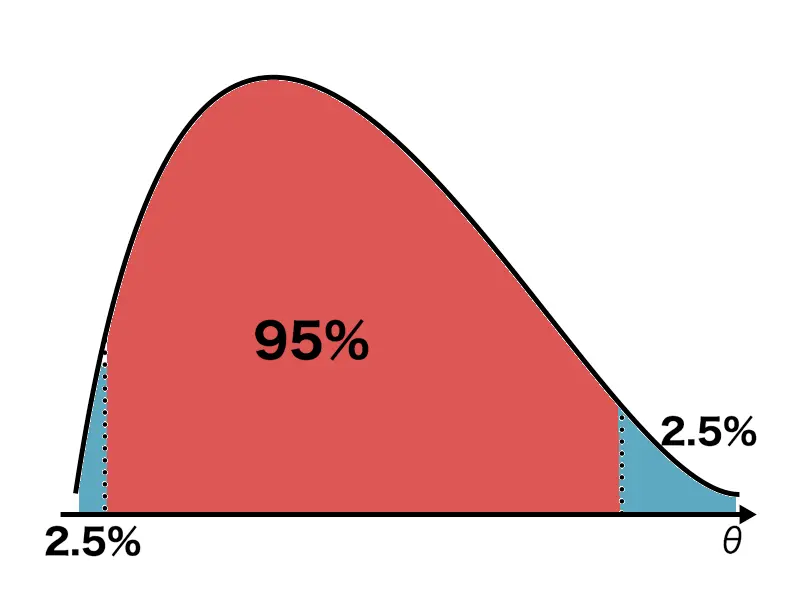
等裾事後信用区間には「信用区間を考えたとき、最頻値を必ずしも含まない」という問題点があります。
指数分布を例に考えて見ましょう。指数分布における等裾事後信用区間は以下のようになります。
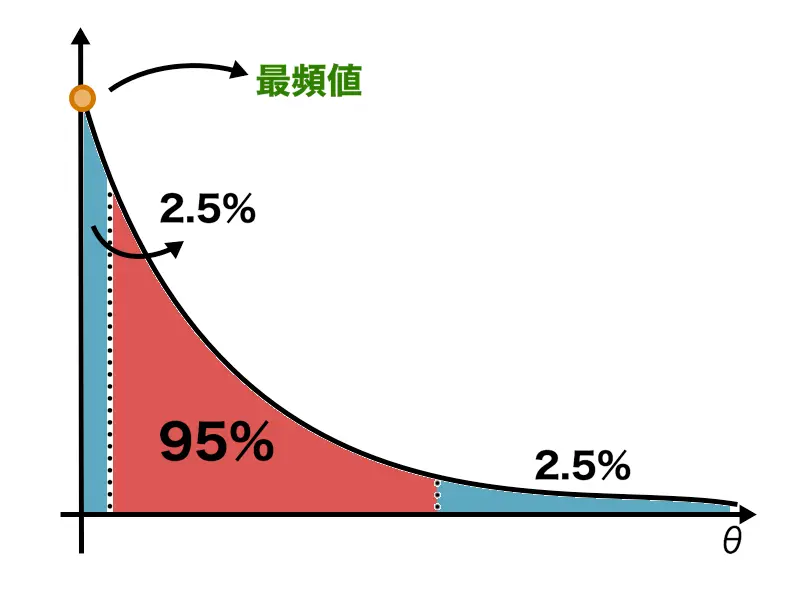
最も取りうる確率が高い(信用度の高い)の部分が信用区間に入っていません。これを信用区間に採用するのは議論の余地がありそうです。
そこで、この問題を打開した最高事後密度信用区間(HPD区間)というものが現れました。
最高事後密度信用区間(HPD区間)
最高事後密度信用区間(HPD区間)は以下のように定義されます。
を満たすような集合を最高事後密度信用区間(HPD区間)という。ただし、は
となるように選ばれる。
以下の画像のように、になるようにの高さを調整するイメージです。
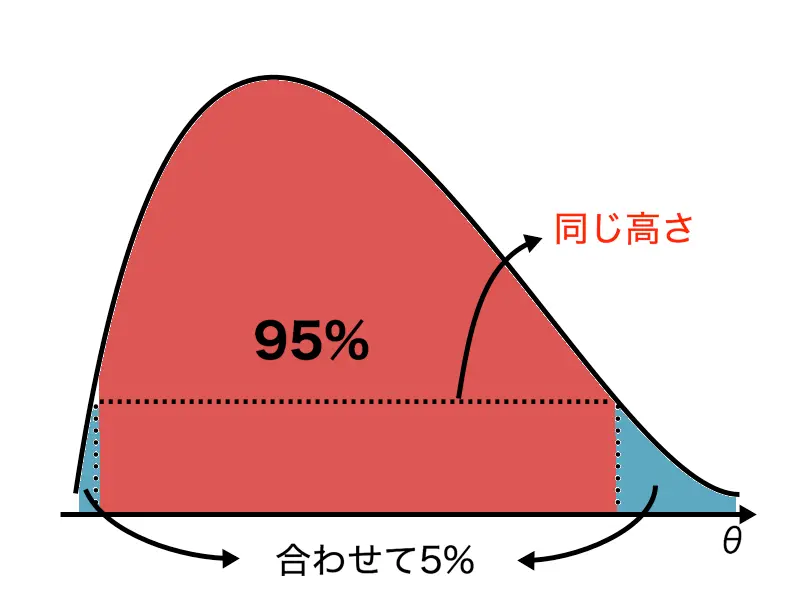
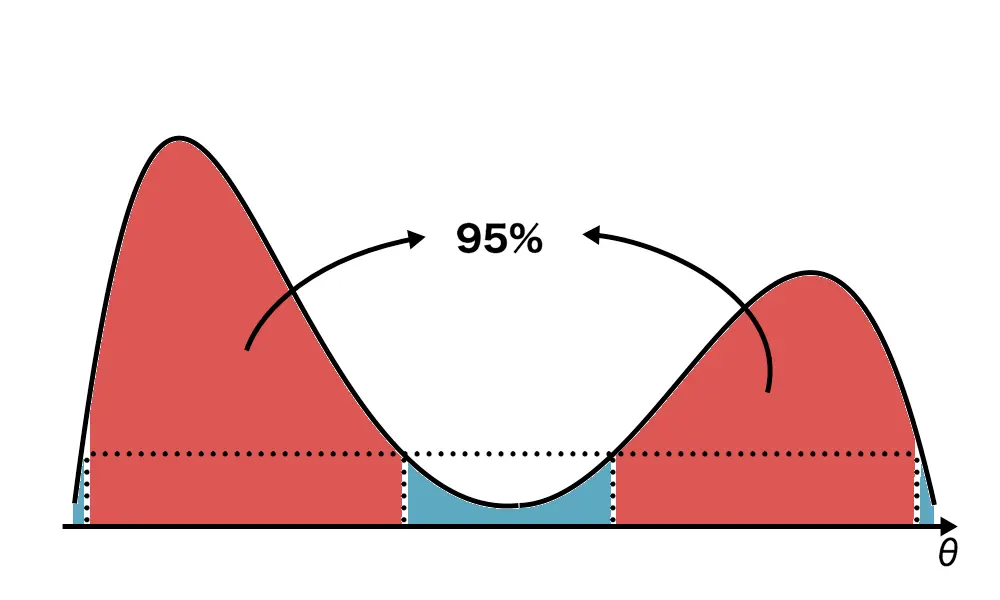
た、事後分布が単峰型でなくても扱うことができます。
カテゴリ: ベイズ統計
関連するサービス
記事の筆者
AVILEN編集部
株式会社AVILEN

